

Overview
This was my second publication in a professional magazine: RPP. RPP (Revista Profesional de Programadores)
This is the first of a 3 articles serie. See the 2nd an 3rd part.

Hace ya dos años que Java salió a la luz. Durante todo este tiempo ha evolucionado en muchos aspectos llegando a convertirse en un factor clave en el desarrollo de Internet. Dado que parece que vamos a tener mucho más Java en el futuro, no está de más que revisemos sólidamente sus fundamentos. Conocerlos nos situará en una posición privilegiada para entender su evolución futura.
En primer lugar debemos tener claro de qué vamos a hablar y de qué no. A lo largo de la serie hablaremos de la Plataforma Java, de su Máquina Virtual y cómo se implementa ésta y, en general, de especificaciones técnicas. Aunque hablaremos de los API, no veremos cómo programar con ellos sino que intentaremos explicar el porqué de dichos API. Es una serie sobre la tecnología Java y sus implicaciones, no sobre programación.
La Plataforma Java
Todo intérprete, servidor, browser de WWW y pronto teléfonos celulares, fotocopiadoras, impresoras (y quien sabe si algún día tostadoras) que empleen tecnología Java, basan su funcionamiento en la Plataforma Java [1]. Éste es el origen y será por donde empecemos.
¿Qué es una plataforma? En términos abstractos, una plataforma es el soporte imprescindible sobre el que podemos ejecutar una aplicación. En términos más simples (y reducidos), podemos verlo como la suma de un hardware y un S.O. montado sobre él. Para saber si dos plataformas son iguales, basta con preguntarse si necesitas recompilar las aplicaciones desarrolladas para una, cuando las quieres ejecutar en la otra. Si la respuesta es afirmativa, las plataformas son diferentes(al menos a nivel de ejecución de código, pues veo que alguno de los lectores se queja de que Windows NT es una plataforma y corre en hardware diverso).
Microsoft Windows, UNIX, OS/2, etc. son ejemplos de plataformas diferentes entre sí.
Ahora que sabemos qué es una plataforma, ¿qué es la Plataforma Java? Pues a la vista de lo explicado arriba, la Plataforma Java es el soporte necesario para que se pueda ejecutar una aplicación Java, y que asegura que allá donde esté instalada podremos correr el mismo código y esperar idénticos resultados.
Si queremos ejecutar código Java en algún equipo (sea un ordenador o un teléfono), lo primero que tendremos que hacer es instalar una Plataforma Java diseñada específicamente para dicho dispositivo. Se monta típicamente, como una capa, sobre la plataforma base ya existente en el ordenador (Figura A).
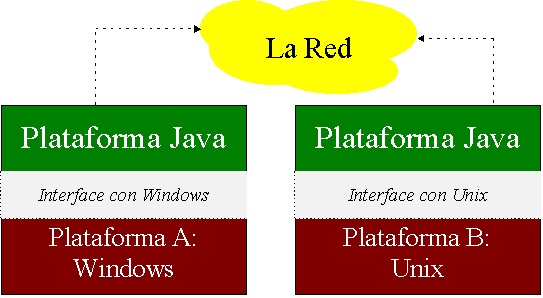
Figura A: La Plataforma Java abstrae las capas inferiores. En este sentido, la Red pierde su heterogeneidad y disponemos de una Red virtual de máquinas idénticas (con las ventajas que esto puede suponer).
Gracias a esta concepción de la Plataforma Java como una capa, se alcanza la independencia de la plataforma que toma como base, algo de vital importancia en un mundo de tecnología tan heterogénea como el nuestro. Al igual que el modelo OSI para interconexión de sistemas en red añade capas que abstraen las capas inferiores, con el fin de hacerlas transparentes, la Plataforma Java hace transparente el equipo entero dando como resultado un equipo virtual idéntico sin importar lo que haya debajo.
Así, donde antes teníamos muchas plataformas y aplicaciones específicas para ellas, que no pueden correr en las demás, ahora tenemos una única plataforma (aunque implementada de forma diferente para cada plataforma base). Esto nos permite ejecutar la misma aplicación en cualquier parte sin tener que portar y recompilar el código.
Partes de la plataforma: MVJ y API
La Plataforma Java consta de dos partes: la Máquina Virtual Java y los ‘Java Application Programing Interface’ (API Java). La Máquina Virtual es la responsable de la portabilidad del código Java. Cada plataforma implementa su propia Máquina Virtual, que interpreta y ejecuta los bytecodes escritos para ésta. Los API son un conjunto de clases predefinidas, que nos permiten escribir y desarrollar código Java al proveer a éste de funcionalidades básicas de uso general.
Aunque toda Plataforma Java emplea la misma Máquina Virtual, no todas disponen de los mismos API. Esto puede sonar paradójico, pues parece romper con la independencia de plataforma de la que tanto alardea Java. De hecho, se rompe. El truco que aparentemente salva todo es la distinción entre diversos API.
El ‘core API’ (también conocido como ‘API base’ o ‘applet API’) es aquél que TODA plataforma java debe incluir como mínimo y que lo constituye el API del JDK 1.0.2 de Sun. Una aplicación que sólo haga uso de estos API funcionará en cualquier sitio.
Por otro lado están las extensiones standard del API que son opcionales pero que, con el tiempo, pueden llegar a formar parte del API base.
Finalmente está el Embedded API, destinado a dispositivos de electrónica de consumo con menos recursos (memoria pequeña, sin pantalla, sin conexión a la red, etc.) como Ordenadores de Red, impresoras, fotocopiadoras, y teléfonos celulares. Parece que Java terminará, finalmente, cumpliendo la misión para la que fue creado (aunque Sun todavía no sale de su asombro, seguro).
Ejemplos de plataformas Java
Para asentar ideas, vamos a hablar de algunas implementaciones posibles de la plataforma.
La primera en la que podemos pensar es en la que tenemos (si realmente nos gusta Java) instalada en nuestro ordenador. De hecho, tenemos varias. Una será la proporcionada por nuestro browser de Web, que incluye una Máquina Virtual y el API necesario, suficiente, y de uso restringido, para que podamos ver applets pulular en pantalla. Otra será la incluida en nuestro sistema de desarrollo de aplicaciones Java (JDK), con el API al completo. En esta última implementación, la forma de ejecutar un programa será lanzar el intérprete pasándole como argumento la aplicación que queremos correr. El intérprete emulará la Máquina Virtual a la que pasará el código, para que lo ejecute. En todas estas implementaciones, la MVJ se emula por software.
Otra posible realización de la Plataforma Java es la propia de los dispositivos de consumo. En esta, la implementación software de la Máquina Virtual se sustituye por una implementación hardware basada en un microprocesador Java que ejecuta los mismos bytecodes, pero mucho más rápido. La propuesta de Sun a este respecto es picoJava, un conjunto de especificaciones sobre cómo llevar Java a chips de silicio. Estos circuitos integrados (de la familia JavaChips) toman como soporte JavaOS, un sistema operativo escrito íntegramente en Java (o eso dice Sun) y que realiza las tareas típicas de planificación de procesos y gestión de recursos, además de proveer funcionalidades gráficas de ventanas, acceso a red, sistema de ficheros, etc.
Como vemos las posibilidades son múltiples y están en continua expansión, pero la idea base (la Plataforma Java) es la misma. No nos dejemos impresionar por tal abundancia (más bien, alegrémonos) y sigamos con la revisión.
La Máquina Virtual Java
Ya conocemos la plataforma y sus partes, pero ¿cómo se implementa y funciona todo eso en la práctica? Lo veremos más claro tras hablar de la Máquina Virtual Java (MVJ).
La Máquina Virtual Java es una máquina imaginaria que se implementa, típicamente, por emulación software en una máquina real (por ejemplo un ordenador). Esta máquina ejecuta bytecodes, un código máquina propio de la MVJ, diseñados para ser eficientemente interpretados. En cualquier caso, la tendencia actual es la compilación JIT de los bytecodes a código nativo o, como veíamos antes, su ejecución con soporte hardware.
Si echamos un vistazo a las especificaciones de la Máquina Virtual Java [2] encontraremos tres partes: arquitectura, formato de los ficheros .class, y el conjunto de instrucciones.
Arquitectura de la Máquina Virtual
Todas las máquinas computadoras se suelen segmentar en tres bloques funcionales: CPU, memoria y E/S. En el caso de la MVJ no es fácil realizar esta separación. Si bien es fácil encontrar la CPU, no lo es tanto encontrar claramente definida la memoria y mucho menos la E/S. En cualquier caso una separación en bloques clásicos de la MVJ nos ayudará a comprenderla mejor, y es lo que vamos a hacer.
La CPU: el corazón de la MVJ
La MVJ (además de muchas otras tareas de alto nivel) emula una CPU, mitad RISC, mitad CISC, de 32 bits y sólo 4 registros, que realiza operaciones basadas en pila.
El ciclo de instrucción consta de 2 fases, búsqueda de opcode (código de operación) y ejecución del mismo. Este ciclo es repetido indefinidamente por la MVJ hasta la finalización de la misma, característica propia de toda CPU.
Todas las instrucciones que ejecuta constan de un código de operación de un único byte y de operandos opcionales, por lo que el número de instrucciones es reducido (inferior a 256 por motivos obvios). Algunas de estas instrucciones realizan operaciones de alto nivel, como estructuras de salto condicional tipo case, mientras que otras son muy simples, como cargar un valor en la pila. Veremos más detalles cuando hablemos del conjunto de instrucciones en el próximo artículo de la serie.
Los cuatro registros de que dispone la CPU (PC, vars, optop, frame) son referencias a memoria de 32 bits (registros de 4 bytes), por lo que sólo se pueden direccionar hasta un máximo de 4Gb.
El registro PC (contador de programa) apunta siempre, como en todas las CPUs, al siguiente bytecode a ejecutar. Este bytecode pertenecerá al método actualmente en ejecución, lo que nos debe llevar a pensar en la obviedad de que un programa Java no es más que una sucesión de llamadas a métodos, en las que se ejecutan secuencias de bytecodes. Y sin embargo, pese a la obviedad, debemos tenerla muy presente en lo sucesivo. Pero sigamos con lo nuestro…
El registro vars apunta al espacio de datos (al que las especificaciones llaman espacio de Variables Locales). La CPU dispone de instrucciones que permiten mover datos desde este espacio a la pila y al revés. En este espacio de memoria se guardan las variables que son locales al método en ejecución. Cuando el método finaliza, estas variables se pierden.
El registro optop apunta a lo alto de la pila. Esta estructura se emplea para realizar todas las operaciones típicas de la CPU (aritméticas y lógicas, entre otras).
Los tipos de datos con los que puede trabajar esta CPU son los básicos de Java (byte, short, int, long, float, double y char) y dos tipos nuevos: Object y returnAddress, ambos de 4 bytes. Object (aunque nos referiremos a estos tipos como objectref en lo sucesivo) es una referencia a un objeto Java (un puntero de 32 bits a un handler del objeto en la implementación de Sun, pero podría ser un índice a una tabla o cualquier otra cosa). returnAddress es un tipo de dato empleado por instrucciones dedicadas al manejo de subrutinas.
El registro frame apunta al entorno de ejecución del método activo. Esta estructura de datos guarda información sobre linkado dinámico, retorno normal del método y propagación de errores, así como información de la clase a la que pertenece, su nombre, etc. Al contrario que los anteriores, frame no es un registro típico en una CPU. De hecho, y como vamos a ver en seguida, está muy ligado a Java.
Básicamente, ésta es la CPU que emula la MVJ. Pero la MVJ es mucho más que una CPU que ejecuta bytecodes. Java es un lenguaje orientado a objetos y esto queda reflejado en la MVJ.
La unidad software en Java es la clase. A nivel de ejecución, sin embargo, la unidad fundamental ya no es la clase sino el método (¿aún lo dudaba alguien?). La MVJ ejecuta en todo momento un único método. Cada método tiene su propio espacio de variables locales (que será liberado cuando finalice el método), así como su propia pila y su propio entorno de ejecución.
El entorno de ejecución contiene referencias, en la tabla de símbolos de la MVJ, del método y la clase a la que pertenece, útil para el linkado dinámico.
También guarda el estado de los registros del método que llamó al método actual (método llamador), con el PC actualizado a la instrucción siguiente a la llamada. Si el método finaliza sin errores, los registros de la CPU se actualizan con estos valores y la ejecución continúa con el método llamador (igual que ocurriría con un ret de una subrutina).
Si ocurre una excepción, se buscan en el entorno de ejecución los catch implementados por el método. Si se encuentra alguno capaz de manejar la excepción, se leerá la dirección de comienzo de la rutina manejadora y se pondrá dicho valor en PC, con lo que se producirá el salto. Si no se encuentra ningún manejador apropiado en el entorno de ejecución del método actual, se restaurarán los registros del método llamador y se continuará con la propagación de errores, tal y como si este error hubiera ocurrido en el propio método llamador. El proceso se itera cuantas veces sea necesario hasta que se encuentre un manejador adecuado.
Si no se encuentra ninguno, veremos un conocido mensaje de error en pantalla.
Una excepción puede ocurrir cuando se produce un fallo de linkaje dinámico (p.e. si no se encuentra el fichero .class buscado), un error de run-time (p.e. una referencia a un puntero nulo), por un evento asíncrono de otro thread (como el lanzado por Thread.stop()), o cuando se usa una sentencia throw.
La memoria: necesidades y distribución
Ya conocemos la CPU de la MVJ, ¿qué pasa con la memoria?
Sabemos que se dispone de una memoria de 32 bits, pues éste es el ancho de los registros de dirección de la CPU. Sobre cómo se organiza ésta, la cosa es más difícil y depende fuertemente de la implementación de la MVJ (es decir, de la casa de software que la desarrolló). Sin embargo, podemos inferir abundante y valiosa información de las especificaciones técnicas sobre la MVJ (ver [2]).
Java implementa un linkado dinámico basado en referencias simbólicas. Esto quiere decir que cuando se hace referencia a una clase, un método, o un campo de una clase, no se emplea una dirección absoluta (no linkado), ni tampoco un offset a una base determinada en tiempo de ejecución (linkado). Lo que se emplea es una cadena de caracteres con el nombre completo de aquello que se referencia (realmente, y como veremos en el próximo artículo, se emplea una “firma” que identifica unívocamente la clase, método o campo).
Debe tener, por tanto, una tabla de símbolos con nombres de clases, métodos y campos, acompañados de su posición en memoria, flags de acceso, identificación de tipo, etc. Cuando se referencia un objeto por primera vez, se busca en esta tabla. Si se encuentra, todas las referencias posteriores a este objeto emplearán directamente la dirección de memoria asociada, y no la cadena con su nombre.
Además de la tabla de símbolos, la MVJ debe disponer de un espacio donde se almacenan las definiciones de las clases cargadas por la máquina, el código de sus métodos, los campos estáticos y las constantes definidas en la misma (pozo de constantes, según el formato .class).
Un espacio dedicado a las variables locales, el entorno de ejecución y la pila de operandos es también necesario. El tamaño requerido por estas estructuras de datos se puede calcular en tiempo de compilación. Se agrupan en un bloque conocido como frame en la implementación de Sun. Cada vez que se llama a un método debe crearse un nuevo frame. Es, por tanto, un espacio de memoria dinámico que se adapta muy bien al modo de operación de una pila (Sun define una pila de frames por cada Thread en ejecución, pero esto ya lo veremos más adelante).
Finalmente encontraríamos el heap Java. Éste es el espacio dinámico de memoria donde se localizan las instancias de las clases. Es en esta área donde actúa el recolector de basura, instrumento que emplea la MVJ para eliminar de forma automática las instancias que no son referenciadas más tarde y, por tanto, son innecesarias y pueden borrarse.
Cada instancia va cambiando a diferentes estados, entre los que se pasa según unas normas bien definidas, hasta alcanzar un estado en el que el recolector puede disponer de ella.
En la implementación de Sun, las tablas de símbolos, el espacio de definición de clases y la pila de frames es conocido como la Method Area. No dispone de recolector de basura, por lo que la tendencia es la de traspasar algunos de estos bloques al área del heap, que sí tiene. De esta forma podrían eliminarse, por ejemplo, definiciones de clases que ya no se usan (a estas alturas es muy posible que esto ya se haya hecho).
Como vemos, la memoria de la MVJ está segmentada en diferentes áreas dedicadas a tareas específicas. No sigue el modelo de John Von Neumann de una única memoria para código y datos. Tampoco presenta una arquitectura Harvard con separación de espacio de datos y código aunque, desde luego, es lo más parecido. En definitiva, parece que la máquina es mucho más software que hardware, y presenta por tanto muchas peculiaridades.
E/S de la MVJ
Tenemos la CPU y la memoria: vamos por la E/S. Toda CPU típica tiene un conjunto de instrucciones que permite el manejo del espacio de E/S, ya sea de forma directa o a través de memoria. Estas instrucciones no existen en la CPU que implementa la MVJ (las áreas cubiertas por el conjunto de instrucciones se pueden ver en la Tabla A). ¿Cómo se las arregla entonces para emplear periféricos (pantalla, teclado, ratón, etc.)? Por ahora sólo diremos que haciendo uso de llamadas al API. Más adelante, cuando hablemos de cómo se ejecuta un programa Java, entenderemos perfectamente este punto. Por el momento, basta con decir que los APIs ‘saben cómo hacer estas cosas’. De todas formas, cualquier mente despierta se dará cuenta de que si la CPU de la MVJ no tiene E/S pero Java es capaz, por ejemplo, de leer desde disco, forzosamente se debe ejecutar código nativo que sepa cómo manejar este dispositivo.
Limitaciones de la MVJ
Además de una limitación de la memoria de 4Gb (32 bits), la MVJ presenta otras limitaciones.
El espacio de constantes (constant pool) de cada clase está limitado a un máximo de 65535 entradas, lo que nos impone límites a la complejidad máxima de una clase. Esta limitación viene impuesta por el tamaño de los índices (2 bytes) al pozo de constantes, que emplean algunas instrucciones de la CPU de la MVJ (hablaremos más del pozo de constantes cuando veamos el formato .class).
La cantidad de código por método también está limitado a 64Kb, debido a que los índices de la tabla de excepciones, tabla de números de línea, y tabla de variables locales son de 2 bytes.
Para finalizar con las limitaciones, diremos también que los argumentos pasados a un método no deben sobrepasar las 255 palabras.
Tabla A: Conjunto de instrucciones de la MVJ.
Áreas cubiertas:
- Movimiento de constantes a la pila.
- Carga de variables locales sobre pila.
- Descarga de pila sobre variables locales.
- Extensión de índice para carga, descarga e incremento.
- Manejo de arrays.
- Instrucciones de manejo de pila.
- Instrucciones aritméticas.
- Instrucciones lógicas.
- Conversión de tipos.
- Control de flujo.
- Retorno de métodos.
- Tablas de salto.
- Manipulación de campos de objetos.
- Invocación de métodos.
- Manipulación de excepciones.
- Creación de instancias y chequeo de tipos.
- Monitorización de objetos.El mes que viene, más
En este primer artículo hemos visto la Plataforma Java como el soporte mínimo imprescindible para ejecutar aplicaciones Java, poniendo un especial énfasis en las múltiples formas en las que ésta se puede encontrar.
Y, para comenzar a entender cómo funciona Java, hemos realizado una visita turística por la arquitectura de la Máquina Virtual. Incluso conocemos sus limitaciones. Sin embargo, aún nos quedan cosas por indagar.
En el próximo artículo analizaremos con más cuidado el conjunto de instrucciones esbozado en la Tabla A.
Hablaremos del formato de los ficheros .class y de cómo éstos se cargan en la MVJ. Sobre cómo funciona la MVJ en tiempo de ejecución, hablaremos en el tercer y último artículo de la serie. Y, tomando como base un sencillo programa de ejemplo, pondremos en práctica todo lo aprendido hasta el momento. Si queda tiempo, hablaremos un poco de cómo se está desarrollando actualmente la Plataforma Java (aunque para ello nada mejor que los artículos de Ricardo Devis, en esta misma revista) y sus posibles repercusiones en el futuro (haremos algunas cábalas, aunque bien fundamentadas).
Pero todo esto será en próximos números. Hasta entonces.
Bibliografía:
Las referencias listadas a continuación se pueden encontrar en formato .PDF en JavaSoft: http://www.javasoft.com/.Como especificaciones técnicas que son, no pasarán a ser clásicos universales, pero hay que reconocer que están bastante cuidados.
[1] The Java Platform, a White Paper. Mayo, 1996. Su lectura es muy aconsejable (sólo son 24 págs.) para conocer Java con una perspectiva global: todo lo que se cuece (o cocía a mediados del 96) está aquí. Es curioso ver cómo sitúan los API como una capa sobre la MVJ, cuando el API lidia directamente con el S.O. al hacer llamadas nativas. Imagino que así queda más elegante, aunque en mi opinión no hace más que confundir.
[2] The Java Virtual Machine Specification. Agosto, 1995. Son las especs de la MVJ (unas 83 págs.). Cubren las áreas necesarias para garantizar la compatibilidad de implementaciones ajenas, pero de guías de diseño, nada de nada (o sea, que tendremos que echarle mucha imaginación en el diseño interno, pero que cumpla lo que allí dice). Era previsible.